
본 문서에서는 상황에 따른 다양한 Tuning 사례를 안내 합니다.
Tuning 사례
1. WHERE 절 함수 변환
EXAMPLE
|
SELECT * FROM T
WHERE C1 = NVL(?, C1)
|
NVL, JOIN Prediacate로 인해 selectivity 계산이 부정확해집니다.
1.1. ? = NULL
?가 NULL이면 C1=C1, selectivity는 1 입니다.
? is NULL이면 항상 true 입니다.
1.2. ? is not NULL
?가 NULL이 아니면 C1=? 입니다.
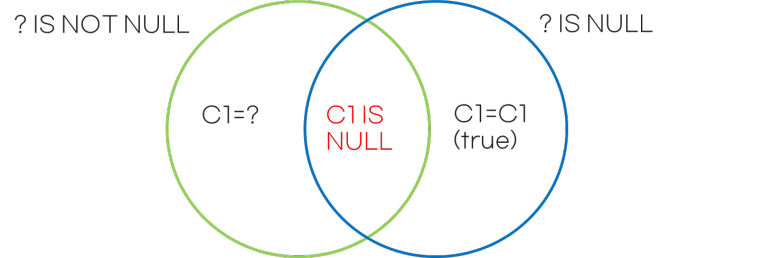
Where 절 함수는 'C1=?' 또는 '? is NULL' 로 변경할 수 있습니다.
2.통계 분포가 고르지 못한 경우
2.1. 조건문의 Selectivity
EXAMPLE
D.START_DATE <= '20130521' AND
D.END_DATE >= '20130521’
위 조건을 만족하는 실제 Row 개수 확인 결과 입니다.
또한 통계 정보에서는 이상이 없음을 확인할 수 있습니다.
|
SQL> SELECT COUNT(*) FROM TSFA_ROUTECUST_MST
WHERE START_DATE <= '20130521' AND END_DATE >= '20130521';
COUNT(*)
---------------
68962
1 row selected.
Execution Plan
------------------------------------------------------------------------------------------------------------------
1 COLUMN PROJECTION (Cost:181, %CPU:0, Rows:1)
2 SORT AGGR (Cost:181, %CPU:0, Rows:1)
3 FILTER (Cost:181, %CPU:0, Rows:1)
4 INDEX (FAST FULL SCAN): PK_TSFA_ROUTCUST_MST (Cost:180, %CPU:0, Rows :69200)
|
START_DATE와 END_DATE 조건을 따로 제시합니다.
|
SQL> SELECT COUNT(*) FROM TSFA_ROUTECUST_MST WHERE START_DATE <= '20130521';
COUNT(*)
---------------
68962
Predicate Information
--------------------------------------------------------------------------------
3 - filter: ("TSFA_ROUTECUST_MST"."START_DATE" <= '20130521') (1.000)
SQL> SELECT COUNT(*) FROM TSFA_ROUTECUST_MST WHERE END_DATE >= '20130521';
COUNT(*)
---------------
68962
Predicate Information
--------------------------------------------------------------------------------
3 - filter: ("TSFA_ROUTECUST_MST"."END_DATE" >= '20130521') (0.000)
|
END_DATE값 분포입니다.
모든 Row가 '20130521' 조건을 만족합니다.
|
SELECT COUNT(*), END_DATE FROM TSFA_ROUTECUST_MST GROUP BY END_DATE;
COUNT(*) END_DATE
---------------- ----------------
1 21030513
68960 99991231
1 21030520
|
2.2. 예측 Row 수가 의심될 경우
특정 테이블에 대한 예측 row 수에 이상이 있을 경우, 우선 통계 정보를 확인합니다.
|
select h.*
from sys._dd_histogram h, sys._dd_hist_head hh, sys._dd_obj o
where o.name=‘테이블이름’
and o.obj_id=hh.obj_id
and hh.hist_head_id = h.hist_head_id
order by hh.col_no, h.bucket;
|
통계 정보에 문제가 없을 시, 실 데이터 분포도를 확인합니다.
|
SELECT COUNT(*), C1 FROM T GROUP BY C1
|
|
SELECT MIN(C1), MAX(C1) FROM T
|
분포가 고르지 못할 경우, 통계정보 수집 옵션을 변경합니다.
|
call DBMS_STATS.GATHER_TABLE_STATS(user, ‘T’,
method_opt=>’FOR ALL COLUMNS SIZE {10 이상의 값 권장}’
|
'튜닝' 카테고리의 다른 글
| [Tibero] SQL Tuning (14) (0) | 2023.06.14 |
|---|---|
| [Tibero] SQL Tuning (13) (0) | 2023.06.13 |
| [Tibero] SQL Tuning (11) (0) | 2023.06.12 |
| [Tibero] SQL Tuning (10) (0) | 2023.06.09 |
| [Tibero] SQL Tuning (9) (0) | 2023.06.08 |