
본 문서에서는 통계정보 수집 시 필요한 정보 중 Column level의 분포도를 표현하는
히스토그램에 대해 안내 합니다.
통계정보
2. 필요 정보
2.1. 히스토그램 (Histogram)
특정 변수에 대한 구간별 빈도수를 나타내는 도구인 히스토그램은 Column level의 분포도를
표현하는 통계정보 입니다. 히스토그램을 관리함으로써 옵티마이저의 잘못된 실행계획
생성을 방지할 수 있습니다.
2.1.1. 히스토그램 특징
- 특정값이 집중적으로 분포되어 있을 시 더욱 효율적 입니다.
- 사용자가 Bucket수를 지정할 수 있습니다.
2.1.2. 히스토그램 종류
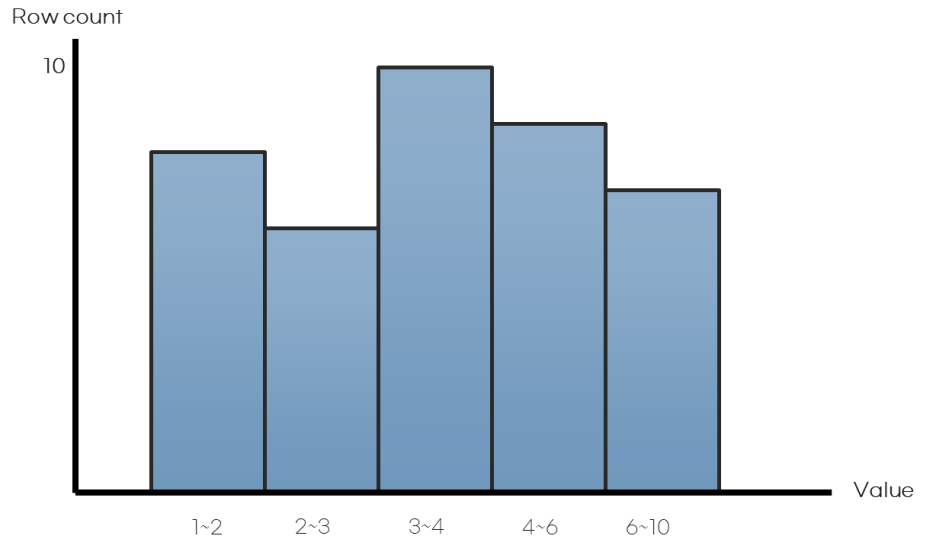
Height-balanced Histogram
Bucket 수보다 변수값이 많은 경우로, Bucket에 한 개 이상의 값들이 분포되어 있을 시 나타나는
형상 입니다. Bucket 내에 여러 값이 분포되어 정확한 빈도 확인은 어려우나 분포가 잘 되어 있는
경우에는 일정 부분 계산이 가능합니다.
Frequency Histogram
Bucket 수와 변수 수가 일치하는 경우로, 동일한 값이 집중적으로 분포되어 있을 시 나타나는
형상 입니다.

2.1.3. 선택도 (Selectivity) 계산
Selectivity는 전체 데이터에서 특정값을 얼마나 잘 선택해 낼 수 있는지에 관한 지표 입니다.
Selectivity를 참고해 데이터베이스 내 인덱스를 생성할 수 있습니다.
Selectivity가 높은 컬럼에 인덱스를 설정함으로써 인덱스 효율을 높일 수 있습니다.
* Cardinality: 데이터 집합 내 중복되지 않는 데이터 수 입니다.
또한 히스토그램을 사용해 Selectivity를 계산할 수 있습니다.
Example

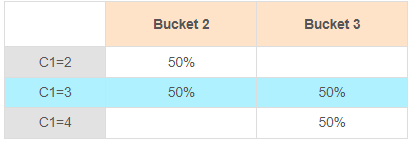
옵티마이저는 C1=3인 row를 전체의 20%라고 예측합니다.
2.1.4. Bucket 설정 정보
컬럼 내 모든 값은 균일하게 분포하고 있다고 판단하므로 기본 옵션은 Bucket 1개 입니다.
히스토그램 수집은 GATHER_XXX_STATS의 method_opt 파라미터로 결정되며
Bucket 사이즈를 지정합니다.
Example
method_opt=>'for all column size 10'
method_opt=>'‘for columns size 10 C1 C2'
2.1.5. 히스토그램 수집 Column type
통계정보로서 컬럼 데이터 분포도를 저장한 히스토그램이 수집할 수 있는 데이터 타입 입니다.
- NUMBER
- CHAR
- VARCHAR2
- DATE
- TIME
- TIMESTAMP
☞[Tibero] SQL Tuning (10)에서 계속됩니다.
'튜닝' 카테고리의 다른 글
| [Tibero] SQL Tuning (11) (0) | 2023.06.12 |
|---|---|
| [Tibero] SQL Tuning (10) (0) | 2023.06.09 |
| [Tibero] SQL Tuning (8) (0) | 2023.06.08 |
| [Tibero] SQL Tuning (7) (0) | 2023.06.05 |
| [Tibero] SQL Tuning (6) (0) | 2023.06.05 |